
Entre Google, Facebook y Amazon, saben los contenidos que busco en internet, por dónde me muevo en la ciudad, cómo soy físicamente, dónde vivo, lo que compro y lo que no. A partir de estos datos y muchos otros, son capaces de inferir mis preferencias personales, mis gustos, mi nivel de ingresos, el estrato sociocultural en el que me encuentro, entre muchas otras cosas. Desde estas inferencias, sus modelos predictivos son capaces de ofrecerme publicidad personalizada en tiempo real, esto es, en el momento que necesito o estoy por necesitar el producto que me ofrecen. Estas herramientas de personalización no sólo las vemos en el terreno de la publicidad, sino que también al ofrecernos la mejor ruta de camino al trabajo o al aeropuerto cuando tengo un vuelo o al restaurante más cercano acorde a mis gustos cuando tengo que comer fuera.
Esta personalización llevada al nivel ideográfico extremo es posible gracias al Big Data y las herramientas de inteligencia artificial (IA). Al proveer constantemente a estas empresas con nuestros datos personales, ellas van construyendo enormes bases de datos a partir de las cuales utilizan modelos estadísticos, muchas veces basados en IA, para identificar subgrupos o subpoblaciones y predecir sus comportamientos. Por ejemplo, estas empresas saben que pertenezco al grupo de hombres de 38 años, calvo, soltero, profesional y con carrera académica, por lo que la publicidad que me ofrecen está seleccionada para este grupo y para mí particularmente. A partir de esta información pueden predecir que si mi sueldo sube al siguiente nivel de ingresos a lo largo de este año pensaré en comprarme un coche, por ejemplo.
Este tipo de tecnología basada en modelos predictivos no sólo se utiliza para personalizar la publicidad en internet y ofrecer consejos personalizados de rutas o servicios, sino que también para personalizar decisiones médicas. La diferencia está en que la información con la que se proveen las bases de datos para establecer este tipo de modelos no proviene de apps ni de las redes sociales de uso público, sino que de nuestros datos biomédicos. Este tipo de bases de datos se elaboran para estudios médicos específicos (muchas veces en el ámbito académico) y si uno quiere participar, tiene que explícitamente dar el consentimiento para que nuestros datos se utilicen anónimamente con esta finalidad. Por otra parte, si hablamos de centros asistenciales públicos, nuestros datos como pacientes, almacenados en fichas clínicas electrónicas, se utilizan para sacar estadísticas (usualmente descriptivas) sobre el alcance de las atenciones realizadas y para estudios epidemiológicos de interés de políticas públicas.
El estudio de cómo personalizar las decisiones médicas y los tratamientos se enmarca hoy en día en lo que se llama medicina personalizada. Corresponde a un modelo médico que busca clasificar a las personas en diferentes grupos, con la finalidad de adaptar las decisiones médicas y tratamientos al paciente individual en función de su respuesta pronosticada o riesgo de enfermedad por el hecho de pertenecer a un grupo específico. Por ejemplo, cuando se prueba un nuevo fármaco por medio de ensayos clínicos es esperable que haya diferentes grupos de pacientes en función de la respuesta al fármaco: probablemente una mayoría para los cuales el fármaco fue efectivo, un grupo menor que no experimentó ningún efecto, y una minoría que experimentó efectos adversos. El desafío de la medicina personalizada es establecer las características exactas que permite distinguir y diferenciar a estos tres grupos de pacientes con la finalidad de desarrollar modelos predictivos. Es decir, poder determinar que un paciente nuevo que posee ciertas características va a reaccionar de una forma o de otra. Esto no es trivial, ya que el modelo de medicina basada en la evidencia (el modelo médico utilizado hoy en día por excelencia) establece que, si en un ensayo clínico un fármaco resultó ser el más efectivo para la mayoría, es el fármaco que debe utilizarse como elección. Esto es lo que genera las prácticas de ensayo y error que muchas veces vivimos como pacientes cuando los médicos nos cambian los tratamientos para “probar” cuál es con el que mejor nos va.
Para poder estimar modelos de medicina personalizada se requiere gran cantidad de datos de las personas y de una gran cantidad de personas. En otras palabras, Big Data, tal como los recolecta Google, Facebook o Amazon. Además, se requiere que estos datos se recopilen y almacenen de forma ordenada y sistemática, con criterios claros y homogéneos respecto de las variables que se registrarán y cómo.
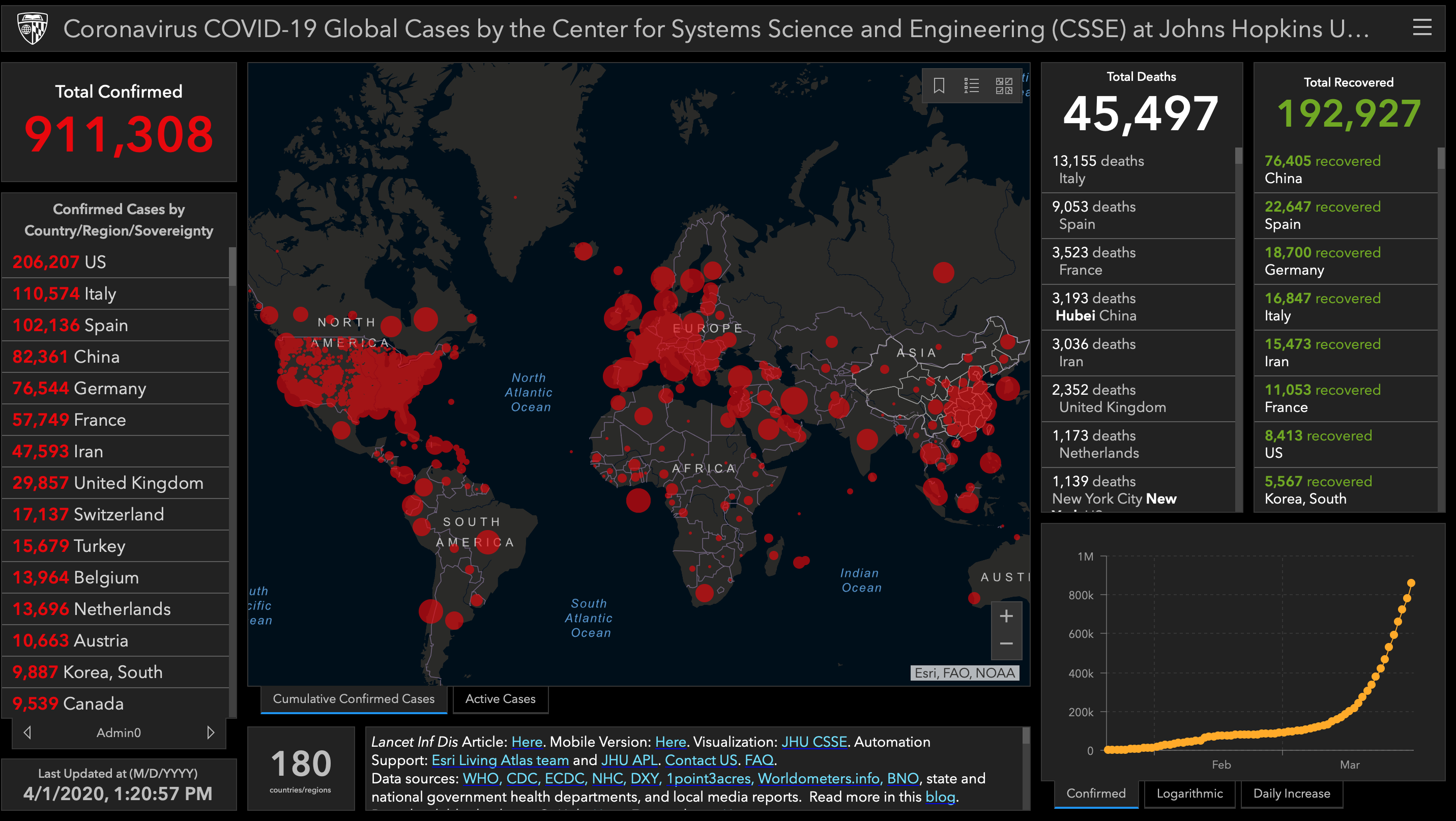
El COVID-19 nos ha pillado por sorpresa. Los criterios de sospecha diagnóstica en base a síntomas fueron evolucionando día a día, al igual que los criterios sobre quiénes debían ser considerados grupos de riesgo y quiénes no. La situación la ha empeorado el no contar con suficientes pruebas diagnósticas para prácticamente toda una población de pacientes potencialmente enfermos. Y es aquí donde hemos desaprovechado el big data y la IA. Nuestros sistemas de salud han estado viendo una cantidad enorme de pacientes a diario y el personal sanitario ha estado registrando todos los datos clínicos de los pacientes en sus fichas electrónicas. En otras palabras, han estado generando big data desde hace semanas. ¿Qué se ha hecho con esa enorme cantidad de datos aparte de calcular las cifras de pacientes diagnosticados y fallecidos (estadísticas descriptivas y datos epidemiológicos)? Sospecho que no mucho más. En España, más de una semana han tardado en darnos datos de mortalidad separados por grupo etario. Más de una semana para decirnos lo mismo que se venía dando en otros países, que el grupo de mayor riesgo es el de la tercera edad.
Con un buen personal técnico especializado en informática y análisis de datos, y con todos los datos que el personal sanitario ha estado registrando en las fichas electrónicas de los sistemas de salud, mucho se podría hacer. Por ejemplo, desarrollar pruebas de screening en base a síntomas y signos, detectar factores de riesgo y factores protectores, determinar medidas escalonadas de tratamiento según el riesgo de los pacientes, lo mismo en cuanto a medidas preventivas, etc. Imaginad por un momento que un grupo de analistas de datos tipo think tank se hubiese puesto a trabajar con estos datos. Por ejemplo, se podría haber diseñado una app web para que los profesionales sanitarios la utilizaran, y la misma app, a partir de la entrada de datos que ellos mismos realizarían, estimara predicciones y recomendaciones para los pacientes, comparándolos con la información que ya tiene almacenada en la base de datos, construyendo, de esta forma, cada vez modelos más precisos al contar cada vez con más datos e información de los nuevos pacientes que se van añadiendo. Sé que diseñar una app puede tomar tiempo y varias pruebas, pero aquí estoy hablando de una app no para uso comercial, sino para uso por el profesional sanitario como una forma urgente de dar respuesta a la demanda de una pandemia. Es más, ni siquiera una nueva plataforma sería necesaria, basta ya con el sistema de fichas electrónicas que ya se utiliza.
El ejemplo anterior corresponde al de una medida para favorecer la toma de decisiones expeditas por parte del personal sanitario ante la avalancha de nuevos casos y la saturación del sistema, con la finalidad de dar respuesta a ello sin tener aún una cura ni cursos clínicos de acción claros. Sin embargo, medidas preventivas y de contención también pueden ser implementadas con estas tecnologías. Por ejemplo, Taiwán relacionó las fichas clínicas de la base de datos del seguro nacional de salud con los registros de aduanas e inmigración para identificar y evaluar a las personas que recientemente habían viajado desde China y habían buscado atención médica o habían mostrado signos de enfermedad respiratoria grave.
De manera similar, Mohamad Ali Hamade del Foro Económico Mundial nos advierte que las herramientas de IA pueden ser utilizadas para procesar la gran cantidad de datos en línea de los sistemas de salud pública, bases de datos de población y registros de transporte. Agrega que las plataformas automatizadas de vigilancia de enfermedades ya nos permiten rastrear y reconocer la propagación del COVID 19 a nivel mundial a través de herramientas de IA, y que han podido predecir la propagación de COVID 19 más rápido que la OMS y que el CDC de EE.UU. En este sentido, China y Corea del Sur ya han implementado tecnologías de geolocalización para monitorear y predecir las localidades donde pueden aparecer nuevos brotes.
Si lo profesionales sanitarios que nos dedicamos al análisis de datos contáramos con la colaboración de las 5 grandes tecnológicas (Facebook, Google, Amazon, Microsoft, Apple) y los datos que ellos poseen y si además existiera la voluntad política, perfectamente podríamos relacionar los datos clínicos con los datos personales y de desplazamiento recopilados de las redes sociales, lo que nos permitiría estimar predicciones aún más detalladas y precisas respecto de los perfiles de riesgo y los resultados de la atención sanitaria. Esto sin duda plantea ciertas interrogantes, ¿estamos dispuestos a ceder nuestros datos para estos fines? ¿Están las 5 grandes dispuestas a compartir sus datos y modelos con fines de políticas públicas o sanitarias?

Volviendo a la inmediatez y a la necesidad de tomar decisiones médicas en el momento álgido de la pandemia, ¿dónde han estado las 5 grandes para ofrecer soluciones como las que planteo a lo largo de este artículo? ¿Nos han ofrecido a un grupo de think tanks expertos en análisis de datos que estén dispuestos a ayudar a los gobiernos, por ejemplo, al español, para contener la pandemia en tiempo real? ¿Se les han ocurrido a los gobiernos ideas como estas y han buscado ayuda en las 5 grandes?
Creo que en los momentos más perentorios de contención de la pandemia hemos desaprovechado las ventajas del big data y de la IA. Es más, como probablemente diría Alan Turing, les hemos fallado fallado a las máquinas, ya que ellas están para servirnos, las hemos desaprovechado.